My Brain, AIs Brain, The Labs Brain


Would you look at that, time flew! ☀️ Summer has started, at least in my house. And I haven't written anything in a hot minute! Well then, let's dive right in. Something I have been teasing, or at least trying to tease, in previous posts was the P2BDB, or Personal Second Brain Database. Now a personal second brain is not a new concept. If you are an avid note taker, you have heard this term many times over. I'll break down the idea in what I think is its simplest form. The idea is to connect thoughts and patterns through some sort of tagging and linking process. Each note taking app has its own way of doing it and some even have a lightweight database for people who love data visualization or mind maps. If you've spent any amount of time on social media and your feed is even remotely like mine, you have seen people connecting their AI Agents to something like Obsidian and "Building an AI's brain" 🧠 Haha, I always get a chuckle out of it because you know, the AI's brain is already built.

So why is this an idea seemingly everyone is trying to do? Ultimately everyone is trying to solve for the same thing. And that is not a brain but rather, a personality and a memory. Remember, AI doesn't remember session to session. Don't get me wrong, context windows are getting larger, so an AI agent can remember more in a session but even that has the caveat that the context window starts to compact earlier tasks and conversation during the context window. So what that means is in a 1 million context window in Claude Code, it starts to compact possibly important information. Just because the AI Agent does its own compaction of tasks and conversations, doesn't mean it's capturing the important parts. There is also the issue that as that context window grows, you're spending more tokens to get a job done. So now you, the human, have to figure out how to manage context, what the AI agent is aware of during a session, and how to optimize it.
The P2BDB 🧠
So what is the P2BDB? It is a pgvector database. "It's a what?!", a pgvector database stands for Postgres Vector Database. A simple way of defining a vector database is it is a search engine for meaning instead of exact words. How does this differ from a structured database such as MySQL or Microsoft SQL? Well a structured database is like a filing cabinet. 🗄️ So when I need to pull data from the file cabinet, I am going to search for a keyword. Example would be I want to see a list of "cars", I would query that database for "cars" and based on the category column, I would get back a list of cars. But let's say that category column also includes "automobile", "vehicle", "sedan", or "van", I would get back none of that, they all can be defined as a car but the database only returns verbatim matches.
So here is the clever trick of vector databases, they take content such as a sentence, photo, song, etc and feed it through an AI model to derive meaning and turn that into a long string of numbers. These strings of numbers are called dimensions. And guess what your AI model thinks in?! Strings of numbers that are meaning of words and use weights to determine if it is on the correct path! Did you know AI large language models don't think in English or whatever language the data scientist speaks? We actually force the LLM to think and speak in English or some other language. They think in these long strings of numbers. So now our vector database is speaking the same language as our LLM. So now when I want to see a list of "cars" I will also see "automobiles", "vans", "sedans", etc because all of those words also mean "car".
This is also called a RAG model or Retrieval-Augmented Generation. This means while I am having a conversation with my AI agent, it has the ability to look back at previous conversations, understand "Is Blackbeard asking me or talking to me about something we have already talked about" and then have additional context about the task at hand vs me having to write really long prompts that include a bunch of information that has been previously completed in the past. This also means that I can use my AI agent to find patterns, standards, issues, vulnerabilities in my infrastructure! Oooo, did I just say "vulnerabilities"?! 🔓 Yup! We'll talk about that more later. This is also used in conjunction with my document repository we talked about in this post that the AI agent can follow and actually see what was completed and how things are built/architected or standard operating procedures, etc.
The Build 🔨
Let's talk about how the P2BDB was built. The goal was simple, Agent-First & Open by design. Agent-first? What does that mean. Well dear reader, in 2026, the world has changed forever. More like the internet and how we build and develop different apps. This is like, a deep rabbit hole for me so maybe I will try and save these thoughts for a one off blog post. The overarching idea is that the P2BDB and the document repository I built with Claude Code are not for me. They are for AI agents. 🤖 So when building, making architectural decisions, compatibility, etc. It was built first for the AI agent and the human (me) was second. So both the document repo and P2BDB have human interfaces but, they're basic and don't break the "Agent-first" over all goal. And honestly, I had the human frontend built and have looked at it a grand total of two times since it was deployed. Once to see what Claude Code had done, and a second time to show a friend.
By the way, this is a new trend. Building for AI agents first and humans second. Right now we are in a time where AI is being bolted on to an application and forced to work around how humans interact with applications. The time is coming where apps will be built AI first, humans second. Do you think that's a scary idea? We are all walking around with AI agents in our pockets now, whether you signed up for it or not it's being forced upon you. Oh man... another one off blog post! The ideas are flowing as my finger tips bang on my still broken keyboard! ⌨️ Okay, back to how P2BDB was built.

So, Agent-First, open by design. Open by design means, I want the ability to attach this P2BDB into multiple frontier models and agents. Why? Because Frontier models and their chat interfaces and code tools is a new data silo. Data silos is the idea that all my data lives in one place. This isn't great. I want to be able to move around based on my own personal criteria from place to place. Like cost! 🪙 If you haven't noticed, we have a new currency on the market. It's called tokens and tokenomics. How much all this context is costing me. So I want the ability to move to a different frontier model or code building interface or OpenClaw to Hermes, etc. The P2BDB gives me my data in a portable way so I can take it all with me to the next best thing. Which these days seems to change on a bi-weekly basis if not almost weekly.

There are also Namespaces or Categories in the vector database. These are things like infrastructure, projects, decisions, security, general, personal, agents, etc. This is how we organize what is going into the P2BDB. This would be the over all meaning for the content. Where did it come from and what is its top level attachment. There is also tags but these are free-form and the agent itself decides what tags the content should have. These tags are also used in the document repository. This helps connect the dots a little more quickly and accurately for the AI agents themselves. If I am working on an app for "cars" and I have data related to "cars" or another app related to "cars", the agent can pull that correlating data from previous "forgotten" sessions. Namespaces, tags, etc, this is going to be specific to you or your organization and what you are doing. Just because I have the namespace "lab", doesn't mean you would or should.
UPDATE: I totally forgot the MCP server!
So how does my AI actually reach this second brain? Through something called an MCP (Model Context Protocol)server. Don't let the acronym scare you, here's the only thing you need to know. Think of the MCP server as a universal wall outlet for AI. You know how any lamp, charger, or toaster works as long as it has the right plug? It doesn't care who made it. The MCP server is that outlet, and the P2BDB is the power behind the wall. Any AI agent — Claude today, something newer next month — just "plugs in," and instantly it can read from and write to my memory. No custom wiring, no rebuilding anything. That's the magic of it: the brain stays put, and I can swap out the AI plugged into it whenever a better one comes along. The memory is mine. The AI is just the tool that plugs in to use it. 🏴☠️
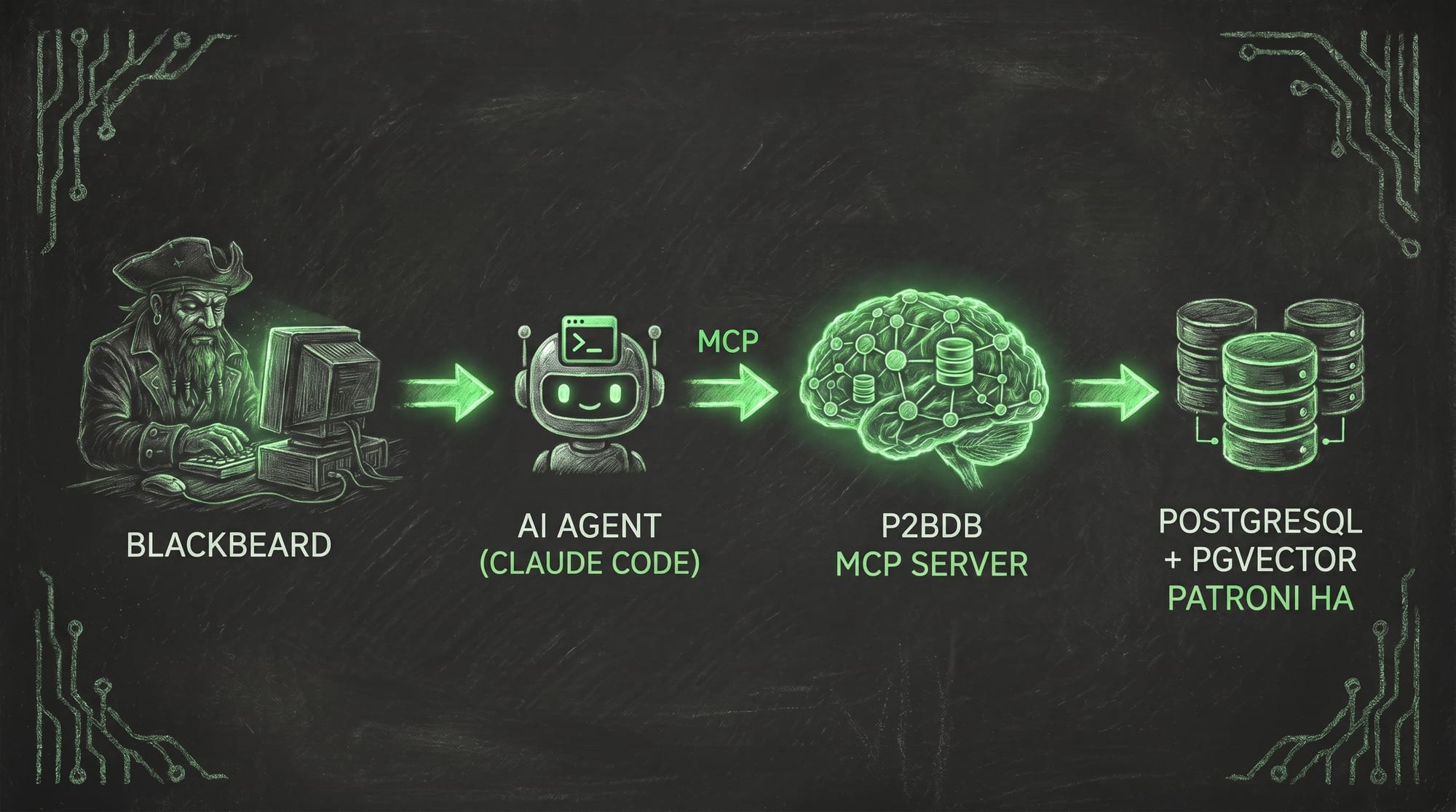
For my more technical friends, here's exactly what we built out in the MCP server
10 MCP tools: store_memory, search_memories, list_recent, get_memory, update_memory, delete_memory, memory_stats, search_related, get_related_links, get_clusters
Parallel REST API (/api/store, /api/search, /api/list, /api/stats, /api/links, /api/consolidation/*, /api/v1/tokens) — same auth
The Evolution 🧬
The P2BDB was built about 3 months ago. And already, it has evolved. In the last couple weeks I have started to deploy multiple AI Agents in the lab. The idea is to have an overarching agent that I go back and forth with on ideas, enhancements, improvements, security, etc, and that over arching AI Agent then delegates work to other AI agents. All of these agents are connected to the same P2BDB. So it is starting to evolve into the Unified Memory Architecture. This is forcing a couple things like optimization, better semantic memory distillation, role based access, and some other stuff. I'm also not forcing any one agent interface to use the p2bdb. Well, I do force it to dump data to the p2bdb but I am not forcing it use the p2bdb on every prompt. Currently I tell the agent to go look at the p2bdb for information. The way I am thinking about it right now is certain agents I will force to go back and look at the p2bdb every time. A good example of this would be the SRE or site reliability engineer agent. 🛠️ It should know, "Have I seen this issue before?", "How did I previously fix this issue", "Is there an SOP for this issue".
Final Thoughts 🏴☠️
So why not something like Notion or Obsidian (What I am writing this blog post in right now actually)? Well first there is the over all goal, Agent-first architecture. Note taking apps are designed for humans and our scattered brains, some more scattered than others. Also, note taking apps are key word searching, there is no meaning behind any one note in my Obsidian vault unless I read it and give it meaning in my mind. Now don't get me wrong, every note taking app has a way of tagging or linking or connecting notes, but those connections are not meaning in the context of AI agents. It would have to crawl the entire database of unstructured data to derive meaning, that's more context, more tokens, and most importantly, more money every time it does it. Note taking apps are single user by nature, connecting multiple AI agents to retrieve, write, or edit data is ultimately going to lead to issues if not full on corruption of your data. You also don't know where that data came from. Did I write this note? Did my overload agent write it? Was it a note from the SRE agent?
It's more a "Use the right tool for the right job". Now this has never stopped me from using my drill as a hammer 🔨 in a pinch, so we all need to remain flexible. And my Obsidian notes are backed up to a git repo which also makes its way to my P2BDB for the agent to gain insight into me as a human being and my hopes, dreams, and goals. So by no means am I telling you to get rid of your notes. Just know that not everything you see people on Instagram, Tik Tok, YouTube is the best way to do something. As I always say, There is a 100 way to do anything in technology, none of them are the best way to do it, some just work better than others.
So how do you build yours? Where's my GitHub link, Blackbeard?! This is your GitHub, text. This blog, other blogs, other open source repos. We live in the age of personal software, don't just use what others give you, make it yours! 🏴☠️ As always, copy paste this article into your agent of choice and have it build it to how you do things and what your goals are, not mine.