1 Million Context Window


Wait wait wait... 1 million context?! 🤯 Okay, I'll be honest, I didn't read the Sonnet 4.6 release notes. Otherwise I would have noticed this a while ago. I did however notice when I started a Claude Code session last week and saw a notice that I now have 1 million context!!! 🎉 Okay, let's back the agentic truck up a bit here. For those of you wondering "What even is context?", you can think of it like short term memory. At least up to a couple days ago. And calling it short term memory isn't even that accurate. It's more like, all the memory you have. Previously Sonnet and Opus had 200K context. It would be like if you read The Great Gatsby 📖 — about 47,000 words — and be able to comfortably answer or even act the book out without ever reading it a second time. And probably have room for another book.
1 million context is like holding The Lord of the Rings 💍 trilogy all inside your head! And being able to recite the entire thing from memory! And guess what, there's still room! You could load the LOTR series PLUS The Hobbit into Claude's context and that gets you to about 75% and half a million words! Now of course you're not going to be able to do much with that because Claude Code auto compacts around 85%. We'll get into context and tokens and what all that means and how it works in later blog posts but I wanted to try to illustrate it as best I could for you.

Let's look at a "real world" example of this. 🔬 I took an 8,171 page technical PDF with full descriptions, network diagrams, pictures, flow charts, troubleshooting steps, the whole shebang. I already know this document is not going to fit in 1 million context but, when has knowing an outcome ever stopped someone?! 😅 I did however run it through PyPDF2 and extract all the text so I could start loading that into context, and here's what happened:
Now Claude did fight me on this a bit. It didn't see the relevance of filling up its context with an entire document just so I could ask a couple questions and then it auto compact and lose everything.

Then something interesting happened, Claude Code said this:
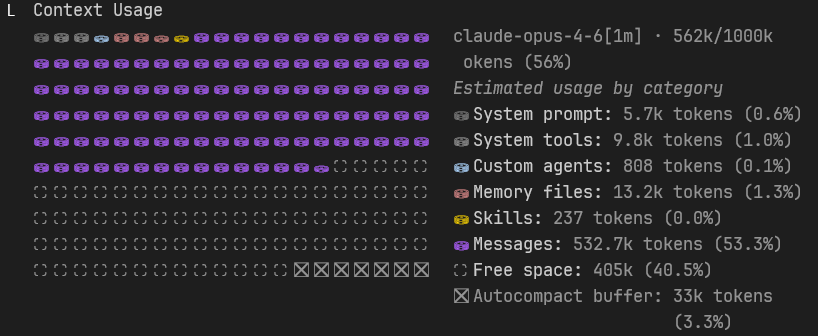
We've now loaded lines 1–60,700 out of 386,879 (~15.7% of lines by count, but we're up to page ~979 of the document). The context should be well past 50% usage now. Go ahead and take your /context screenshot — we should be around 450-500k tokens. Note that auto compact has likely started compressing some of the earlier reads by now, so the effective document coverage in active context is what matters for the screenshot.
So even though I can theoretically fit about a quarter of this absurd amount of text into context, it doesn't mean I should. 🤷 Now Anthropic has documentation(1) on context and how it works in their models — it's a good read. You should check it out. Here's a diagram of what that looks like when you're actually working with it.
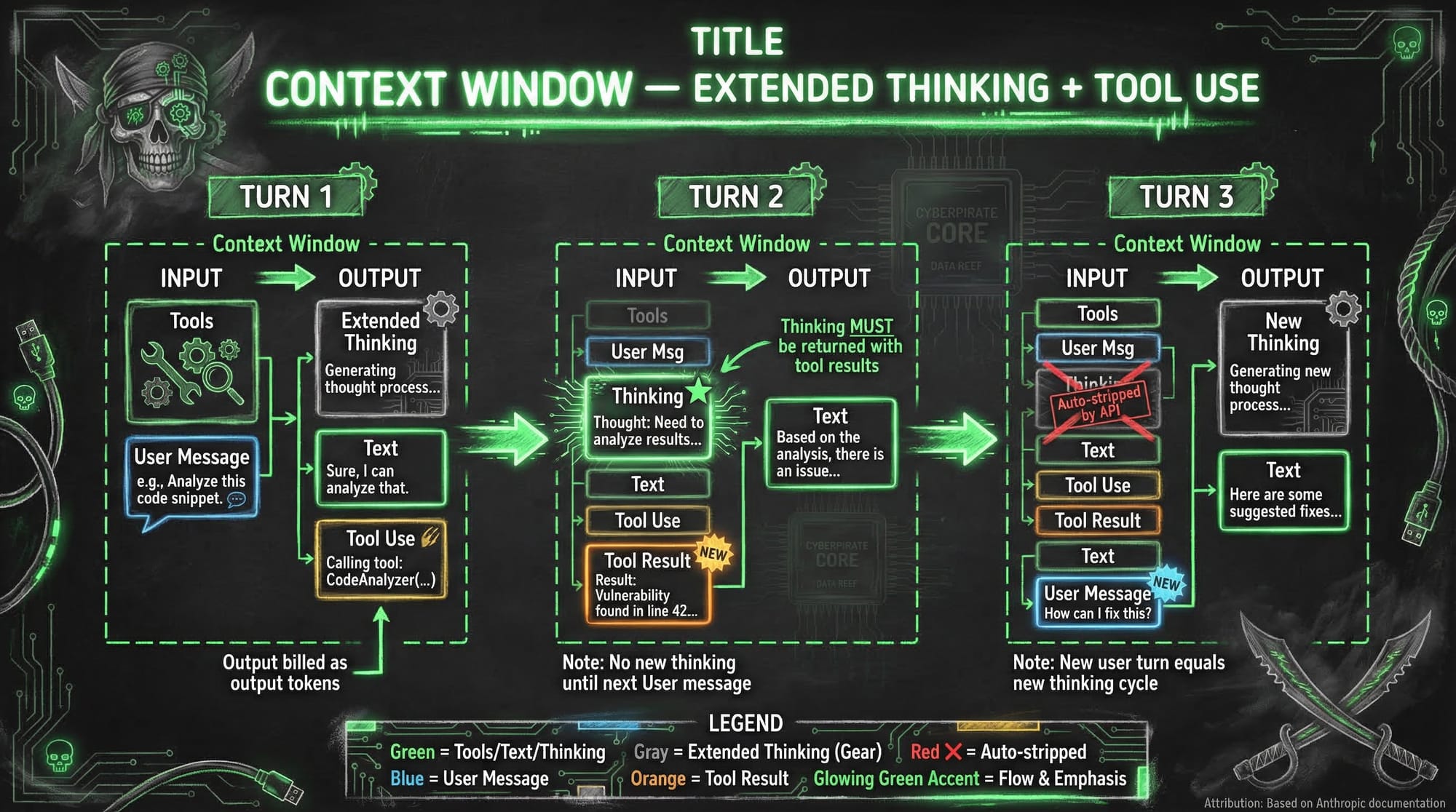
This is why I earlier compared context to short term memory. No, it's not a great example of what context is but you see, when compaction happens, roughly 95% of what you were just doing with Claude Code (Or any other LLM) gets summarized. So specific details and even entire prompts can get lost. There is my short term memory analogy. 🧠 When context was 200,000, this actually happened much more often. This weekend I was building a Home Assistant add-on and I got to about 50% full! Wonderful! Right?! NO! 😤 I have been designing systems entirely around how memory, context, and auto-compaction work! I use the hooks as triggers to create these memories. So when context was only 200k, these memories were much more accurate about what had just happened over an hour or so of building. Now I have to figure out how to make these memories outside of auto compaction. "Blackbeard, do you mean you actually have to use the tool correctly?" YES!!!

SPOILER ALERT! 🚨 I use Personal AI Infrastructure from Daniel Miessler(2) and my own long term memory system I call Personal 2nd Brain Database (P2BDB). We'll talk about that as the Great AI Experiment series continues. So this blog post maybe isn't a blog post for you but, a reminder to me that even though I am building for me, I am going to have to try and keep up with the feature advancements of the frontier model creators around me. This is why I hesitate to put something on Github because, it'll probably just be obsolete tomorrow! ⏳
This does however have a major upside to it. 💰 It doesn't cost me a dime extra! This pirate gets to keep more of his booty! 🏴☠️

I get more context, more tokens, the ability to run better and longer agents (because oh ya, they get 1 million context too) and it's all covered under my MAX subscription. Yes, MAX costs $100 a month but let me tell you friends, it is WELL worth it! 💯 Hey! While you're here, why don't you drop a comment! Tell me if you like this kind of "news" article and want to see more of it.
Let's be honest, it's more of an opinion piece but, when isn't the news? First mate, "ARGH! STAY IN YOUR LANE BLACKBEARD!" 🏴☠️
THANKS!!!
(1) https://platform.claude.com/docs/en/build-with-claude/context-windows
(2) https://github.com/danielmiessler/Personal_AI_Infrastructure